But if everyone claims its AI model excels, benchmarks become less meaningful. So how can companies know which AI systems are the most capable and best-suited for their purposes?
The stakes are high. Understanding AI benchmarks can help guide vendor decisions, identify growth areas and assess whether a model is suitable.
The first path to discernment is understanding the nature of these benchmarks. These benchmarks are standardized tests that measure an AI model’s proficiency in several areas: math, science, language understanding, coding and reasoning, among other topics.
The tests take the form of questions or tasks like summarizing text, completing snippets of code or solving math problems. Just like students take exams to demonstrate what they’ve learned, AI models are put through benchmarks to evaluate what they can do. After an AI model takes the test, it gets a score or percentage for performance.
Benchmarks are important because without them, companies would have to rely on marketing claims or one-sided case studies when deciding which AI system to use.
“Benchmarks orient AI,” Percy Liang, director of Stanford’s Center for Research on Foundation Models, has said at a Fellows Fund event. “They give the community a North Star.”
There are many benchmarks, each targeting a different area of AI capability. Some of the most well-known include the following:
- MMLU (Massive Multitask Language Understanding): Tests general knowledge across a wide range of subjects.
- Chatbot Arena: AI models go head-to-head in answering real-time crowdsourced user prompts.
- HellaSwag: Evaluate a model’s ability to reason and understand context in language.
- HumanEval: Measure how well an AI model can write and debug computer code.
- TruthfulQA: Assesses how often a model gives factually correct answers.
- SWE-bench: Measures software engineering capabilities.
A newer class of benchmarks goes beyond static tests and focuses on agentic capabilities – how well AI systems can reason, act and adapt in complex, multi-step environments. One such example is AgentBench, which evaluates how well AI models perform across different types of real-world tasks, such as planning a trip or booking appointments online.
Read more: Microsoft Plans to Rank AI Models by Safety
When Everyone’s a Winner
In model releases, many companies boast that they have beaten their competitors on selected benchmarks.
For example, Google’s Gemini 2.5 Pro scored 86.7% on AIME 2025, which is a test of advanced mathematical reasoning and problem-solving ability based on the American Invitational Mathematics Examination (AIME).
Google compared the score to OpenAI’s o3-mini, which came in at 86.5%; Claude 3.7 Sonnet, at 49.5%; Grok 3 beta, at 77.3%; and DeepSeek R1, at 70%. These are scores for one attempt at the test.
Google also showed how Gemini fared in Humanity’s Last Exam — a general knowledge exam that tests reasoning, memory, planning, coding, language and ethics to see if a model is approaching AGI — GPQA diamond (STEM reasoning tasks), AIME 2024 and other tests.
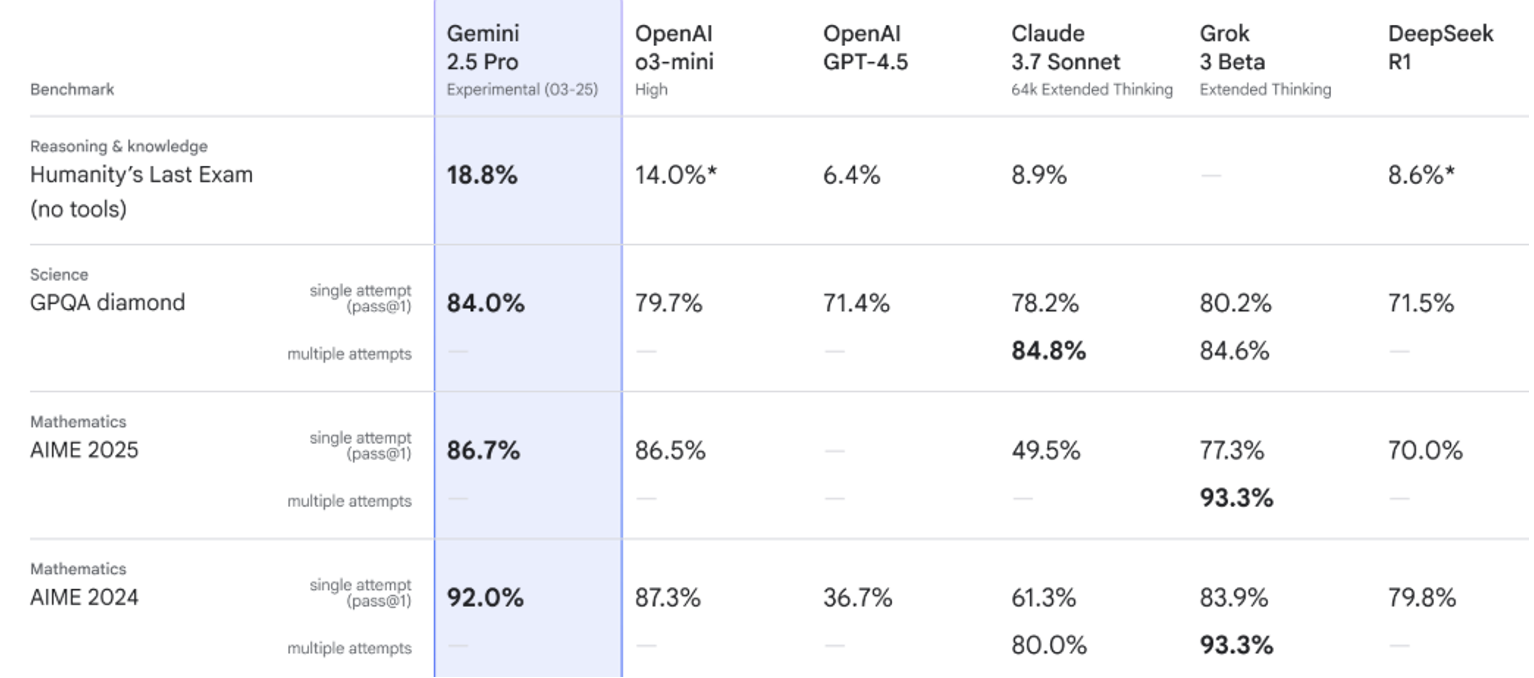
Source: Google
A month earlier, xAI released the performance of Grok 3 Beta compared to rival AI models, which included the same benchmarks. (Grok 3 Beta came out before Gemini 2.5 Pro.)
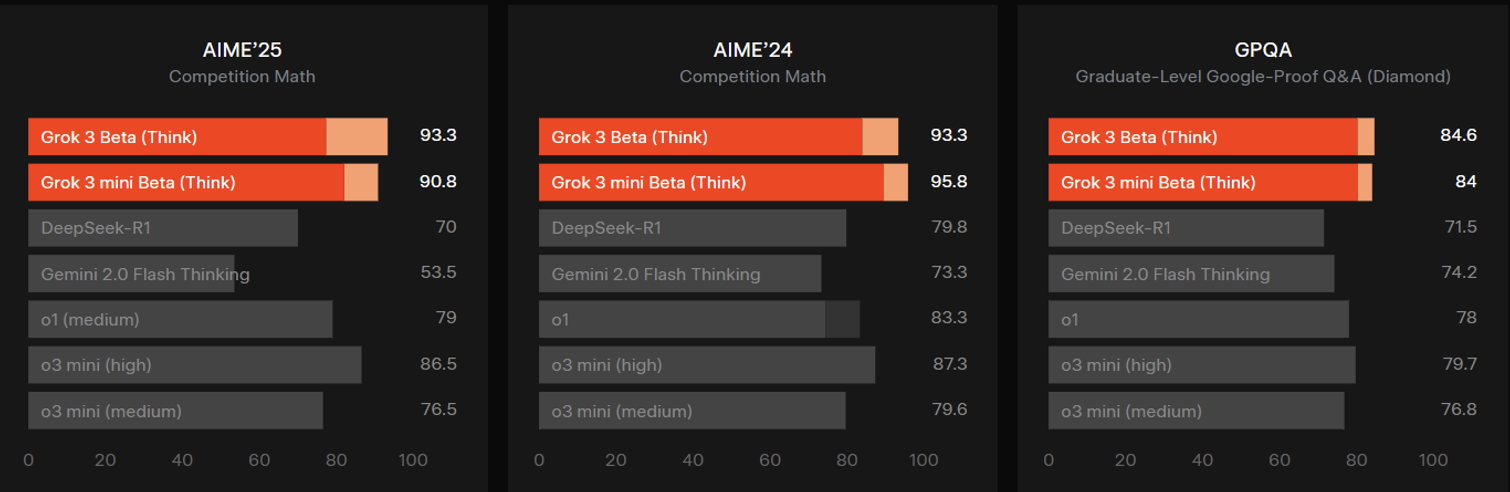
Source: xAI
Adding to the confusion are claims from some researchers that benchmarks could be gamed. A new paper from researchers at Cohere Labs, Stanford and Princeton found that rankings in AI benchmark Chatbot Arena may be systematically biased in favor of a few large AI providers, raising questions about how much trust businesses should place in these scores.
According to the study, Chatbot Arena let a small group of large AI companies — including Meta, Google, OpenAI and Amazon — test dozens of model versions before selecting the best one to display publicly. Meta, for example, submitted at least 27 models before releasing Llama 4.
Since only the best versions are revealed, this artificially inflates scores by more than 100 points, according to the authors.
Where does that leave companies? Marina Danilevsky, IBM’s senior research scientist, said businesses would do well to recognize the limits of benchmarking. “Performing well on a benchmark is just that – performing well on that benchmark,” she said in a blog post.
Companies should also acknowledge that most AI benchmarks test general capabilities when domain expertise could be more useful to business, added Sumuk Shashidhar, a researcher at code repository Hugging Face, in the same blog post.
Hugging Face has released an open-source tool, YourBench, that lets companies develop their own benchmarks to evaluate tasks most salient to their businesses. All that’s needed is for the company to upload documents, and YourBench will generate “reliable, up-to-date, and domain-tailored benchmarks cheaply and without manual annotation,” according to the white paper.
YourBench carries an Apache License 2.0, meaning it is free for commercial use, modification, distribution, as well as for patent and private use. Those who use it must cite the copyright and license.
Read more:




