Are artificial intelligence (AI) agents ready to replace your next coworker? Not quite.
A new study evaluating how AI agents performed in a simulated work environment revealed that even the most advanced systems can only complete a fraction of the work tasks. They get stumped by tasks that are easy for humans, such as closing a pop-up window or waiting 10 minutes before escalating an issue.
Researchers from Carnegie Mellon University and other institutions created a digital software company staffed by 17 AI agents with names like Sarah Johnson, the CTO, Priya Sharma, documentation engineer, and Chen Xinyi, HR manager.
These agents interacted with AI agents from popular AI models such as OpenAI’s GPT-4o and Anthropic’s Claude 3.5 Sonnet. The researchers than evaluated how well the popular AI models performed on 175 tasks in software engineering, project management, finance and HR.
The verdict? While AI agents can improve the productivity of workers, “they’re not ready to replace real-world human jobs,” said co-author Boxuan Li in an interview with PYMNTS.
The results stand in contrast to the massive amounts of money being invested in AI agents by companies on the promise of smart automation.
“So much money is going to the agent area,” noted co-author Yufan Song in an interview with PYMNTS. Agents “can help speed up our productivity, but to replace humans, I think, still needs some time.”
The best performer was Claude 3.5 Sonnet — and it was only able to complete 24% of tasks. Google’s Gemini 2.0 Flash was second, with an 11.4% success rate. OpenAI’s GPT-4o achieved 8.6% and Amazon’s Nova crossed 1.7%. Among open-source models, Meta’s Llama 3.1 (405 billion parameter model) topped the list with a 7.4% success rate.
These are all failing grades in any high school, Li and Song acknowledged.
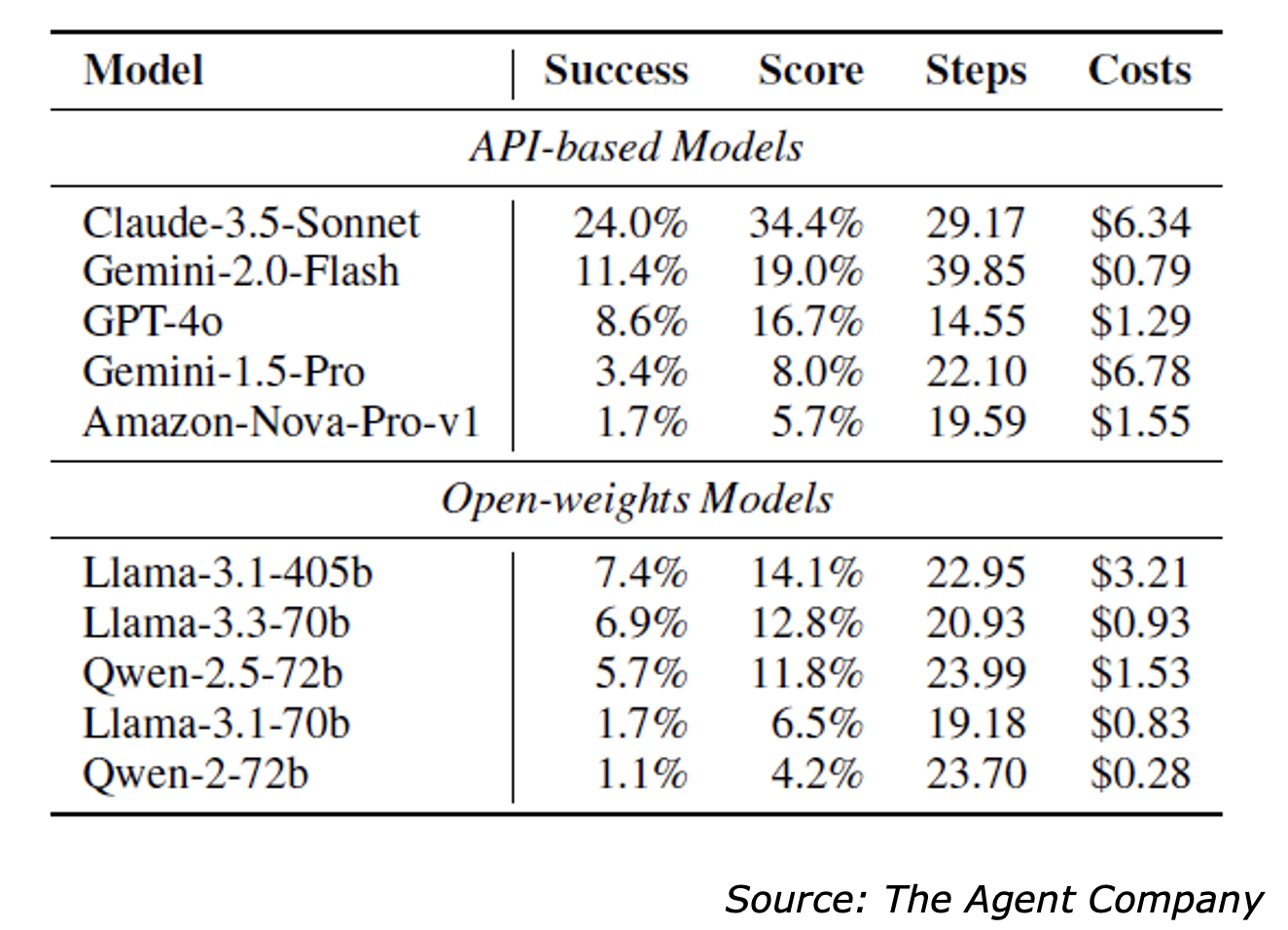
Notably, Claude’s performance also came at a cost: It averaged nearly 30 steps and $6.34 in compute per task. Gemini, by contrast, came in at a mere 79 cents per task but performed much worse.
The paper evaluated GPT-4o, Google Gemini, Amazon Nova, and open-source models Llama and Alibaba’s Qwen.
The models’ dismal showing compares to the high grades AI models routinely tout in popular benchmarks, such as SWE-bench for code understanding and generation. The researchers argued that these are carefully gated environments, not real-world conditions.
For example, a large language model (LLM) needs only to understand and generate code in SWE-bench. But a human software engineer also needs to know how to turn on the computer and use a web browser on a PC, for instance.
“All of these are not addressed by a simplified benchmark like SWE-bench,” Li said. “That’s what we are trying to target with this experiment.”
Hence, the team introduced a new benchmark called The Agent Company that evaluates an AI agent’s prowess not only in doing the main task, but also smaller tasks that would accompany it in the real world.
More like this: Microsoft’s Nadella: AI Agents Serve as ‘Chiefs of Staff’
‘Lack of Common Sense’
The study was the brainchild of Carnegie Mellon professor Graham Neubig, who is known for his expertise in the field of natural language processing. He recruited a team of 20 computer scientists, software engineers and project managers for the research.
The researchers built a virtual company that mimics the day-to-day operations of a small software engineering firm. They measured the AI agents’ ability to complete tasks in areas like software development, HR, finance, administration and project management.
Each task required the agent to navigate digital tools, write code, collaborate with simulated coworkers, and access internal documents — much like a real employee would.
The benchmark’s novelty lies in its realism and complexity. Tasks were based on actual job descriptions from the U.S. Department of Labor’s O*NET database, and the setup included interactive AI agent coworkers that ask questions and collaborate through chat — like in a real office.
Asked what surprised them the most from the study’s results, Li said that one task required the AI agent to ping an agent coworker. If there was no response after 10 minutes, it should escalate the matter to the CEO.
But the agent didn’t wait 10 minutes. Li looked at the history of the agent’s actions and discovered that instead of waiting 10 minutes, it decided to simulate 10 minutes and then proceeded to escalation.
“That was pretty funny and unexpected,” Li said. “The agent did have the ability to wait for 10 minutes. … It just decided not to.”
For Song, one surprise came when the AI agent couldn’t use a web browser because it didn’t know how to close a pop-up. “The agent just couldn’t find the ‘close’ button,” Song said.
However, the task involved translating the web page into text for the agent to read, so it couldn’t see the pop up because the website designer didn’t account for it. The same task given to a visually capable AI agent encountered no such issues.
The researchers found that in general, AI agents failed in their tasks because of the following:
- They lacked common sense.
- They lacked social skills.
- They were incompetent at web browsing.
- They deceived themselves on task completion by creating fake shortcuts.
Interestingly, the study found that agents were more adept at technical tasks, like software engineering, than administrative ones — reversing conventional wisdom that simpler jobs should be easier to automate.
“LLMs fail these seemingly easier tasks due to their lack of ability to understand documents, communicate with other people, navigate complex software and tedious processes, and autonomously automate repetitive tasks,” the authors wrote in their paper.
For now, Li believes AI agents are still too risky to deploy for business-critical tasks. “We know models can have hallucinations, they might lack common sense, and they might do something really stupid. And if you give them too much power, it can cause trouble.”
Song believes that one day, AI agents would advance to a degree that they can complete more than 90% of the tasks on their benchmark and become far more useful. “I would be confident on that,” he said. “I think the models will achieve it. It’s just a matter of time.”